
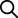

-
DATAWARE™ DV#
분산되어 있는 데이터베이스, 파일, 빅데이터를 별도의 메모리 공간에
가상 데이터 레이어로 통합하고 최신 데이터를 실시간으로 활용할 수 있는
환경을 제공합니다.물리적인 DB 통합에 비해 구현기간이 감소하고, 데이터 소스 변경이 용이하며
보안 측면에서도 가상화된 데이터에 대한 접근 권한을 제어하거나
접근 이력 기록 및 데이터 마스킹 처리를 제공합니다.
물리적 데이터 이동없이 하나의 통합된 데이터로 빠르게 통합
- Silo된 데이터의 실시간 결합
-
-
물리적인 데이터 레이크에서 발생될 수 있는 컴플라이언스 이슈, 무분별한 데이터 복제(물리적인 데이터 이동) 방지와 품질 정합 검증을 위한
실시간 데이터 동기화 및 원천 데이터와의 재결합을 위한 논리적인 데이터 레이크 (Logical Data Lake)를 구성
-
물리적인 데이터 레이크에서 발생될 수 있는 컴플라이언스 이슈, 무분별한 데이터 복제(물리적인 데이터 이동) 방지와 품질 정합 검증을 위한
- 인-메모리 데이터 가공 레이어
-
- 사용자/애플리케이션 Layer와 Data Source Layer 사이에 위치하고 있으며, DV 사용자 권한 분리를 통해 유연한 운영 환경을 제공
- 데이터 가상화 플랫폼
-
-
관리대상 데이터 소스에 대해 활용 권한을 가질 수 있으며, 데이터 소스로부터 Designer를 통해 다중 또는 제한 선택을 하여 VDB (Virtual Database)를 구성하고,
배포된 VDB를 통해 다양한 데이터 소스에 대해 사용자 및 애플리케이션은 하나의 데이터 모델처럼 접근 가능
-
관리대상 데이터 소스에 대해 활용 권한을 가질 수 있으며, 데이터 소스로부터 Designer를 통해 다중 또는 제한 선택을 하여 VDB (Virtual Database)를 구성하고,
-
 Data Virtualization Solution
Data Virtualization Solution
최신 데이터를 실시간으로 활용할 수 있는 가상화 환경 제공
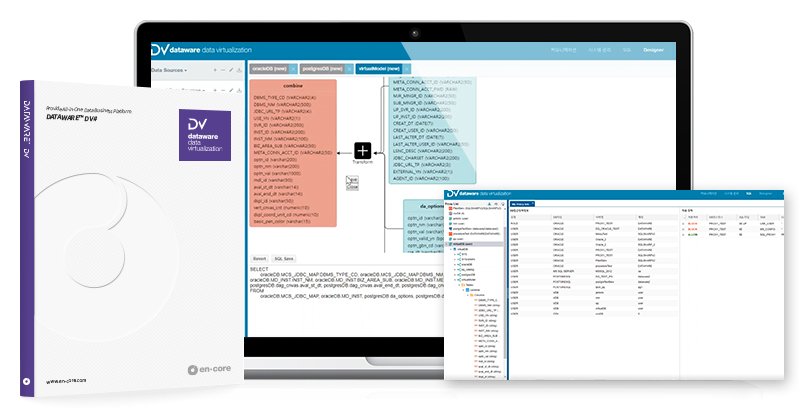
유연한 DB 가상화 구축을 위한 편의 기능 제공
| 01 | 하나의 통합된 데이터로 빠르게 통합 | 02 | 물리적 데이터 이동없이 완전 데이터 결합 |
|---|---|---|---|
| 03 | 무분별한 데이터 복제 방지로 컴플라이언스 대응 | 04 | 접근 권한과 이력 관리 마스킹 처리로 보안강화 |
| 05 | 웹 기반의 유연한 중앙 운영 관리 | 06 | DV#전용 Designer로 편리한 DB 가상화 설계 및 관리 |
| 07 | On-Premise 및 Multi Cloud 환경 등 다양한 구성에 대응 | 08 | Logical Data Lake로 비용 절감 및 기간 단축 |
데이터 가상화 플랫폼으로 신속한 통합 환경 구성
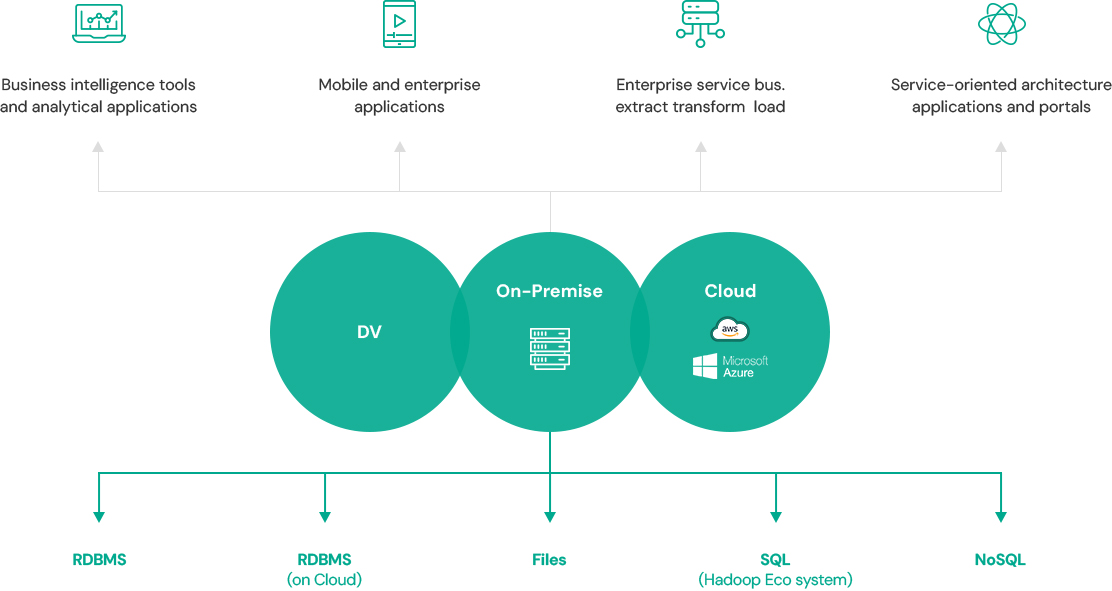
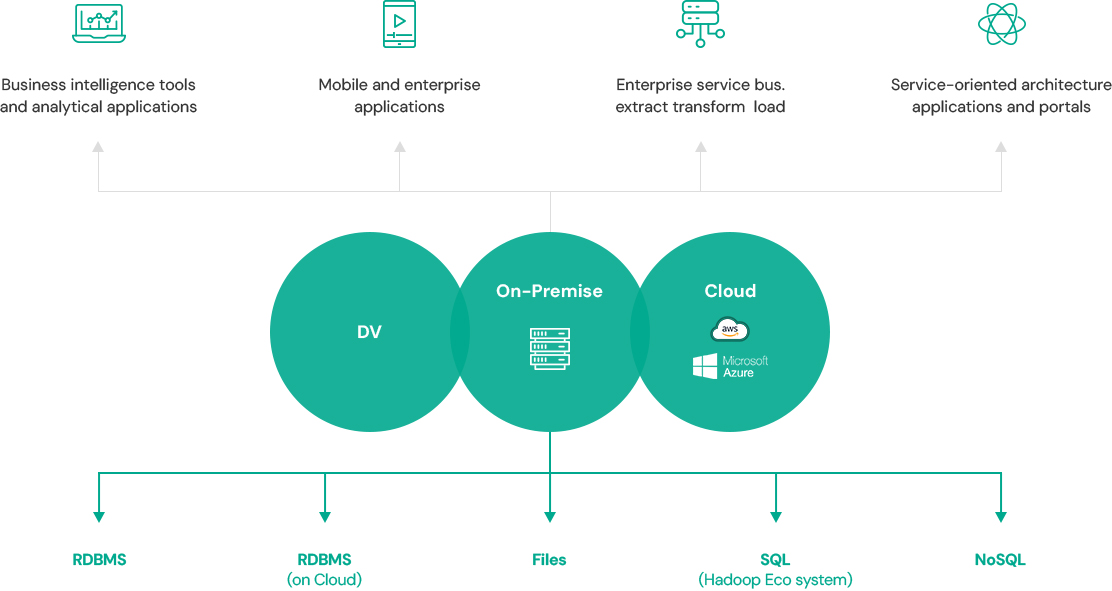
|
DATAWARE™DV#은?
| RDBMS, File, Big Data Platform에 대한 데이터 가상화 | 다양한 데이터 확인을 위한 Web SQL Tool | ||
| 다양한 데이터 소스에 대한 가상 테이블 구성 및 Join | 데이터 접근에 대한 SQL 접근통제, 기록 및 데이터 마스킹 | ||
| 데이터 가상화 구성을 위한 메타데이터 설계 및 관리(Designer) | 성능 개선을 위한 옵티마이징 및 다양한 힌트 | ||
| 성능 최적화를 위한 캐쉬 및 데이터 연결 구성 | 사용자 별 Virtual Database 구성 | ||
| 데이터 접근 및 활용을 위한 표준 JDBC / SQL 인터페이스 | On-Premises, 퍼블릭/프라이빗 Cloud 환경 구성 |
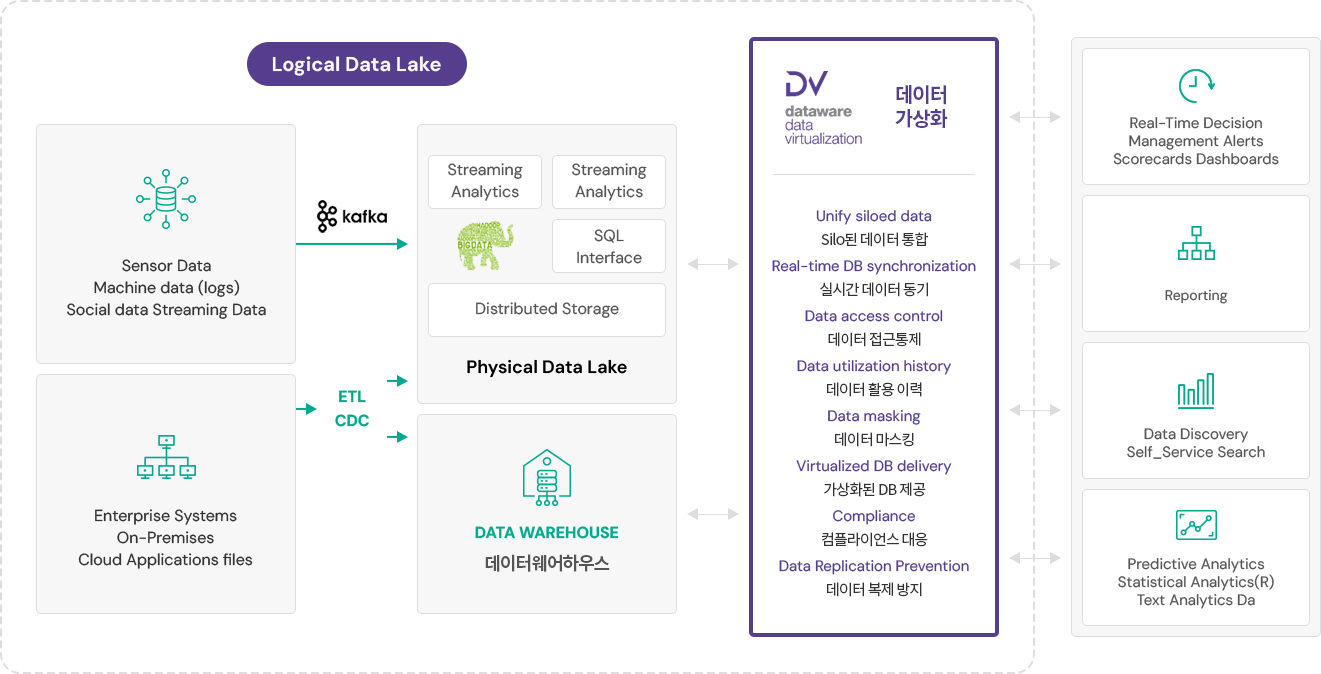
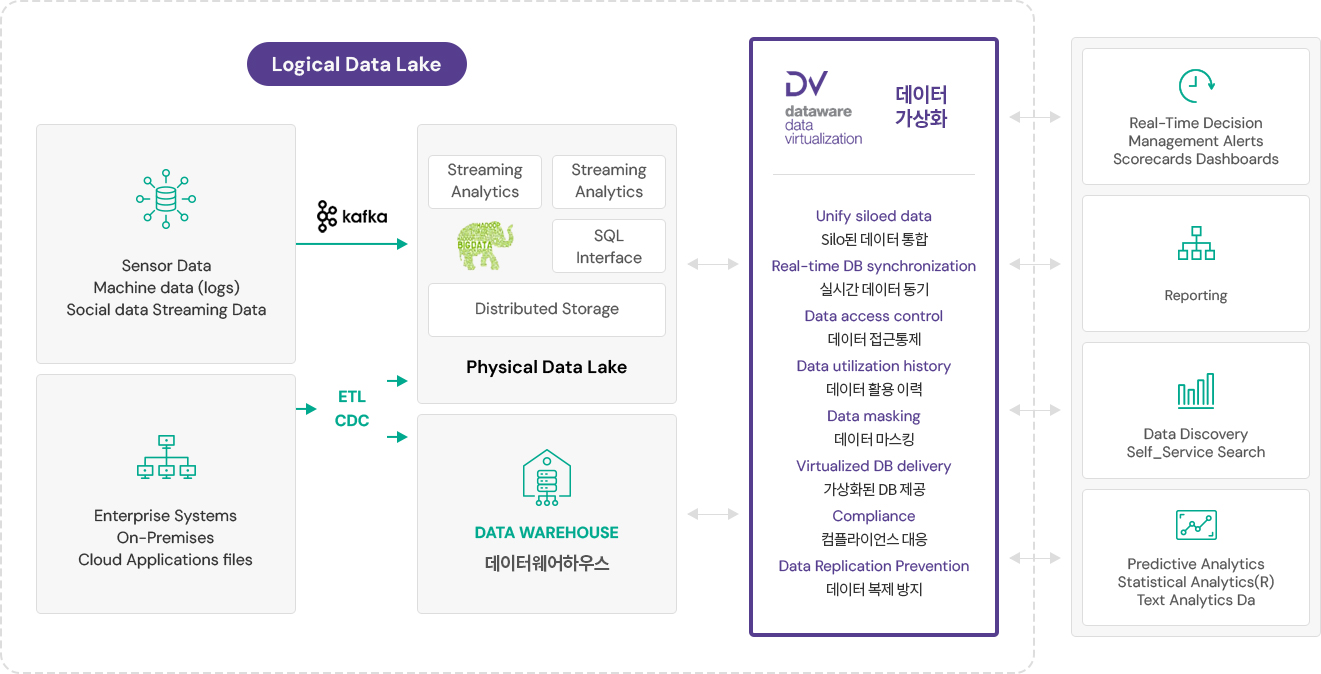
DATAWARE™ DV#을 활용한 논리적 데이터 레이크 구축
DATAWARE™ DV#은 물리적인 데이터 레이크에서 발생될 수 있는 컴플라이언스 이슈를 발생시킬 수 있는 무분별한 데이터 복제와품질 정합 검증을 위한
실시간 데이터 동기화 및 원천 데이터와의 재결합을 위한 논리적인 데이터 레이크 (Logical Data Lake)를 구성할 수 있게 합니다.
|
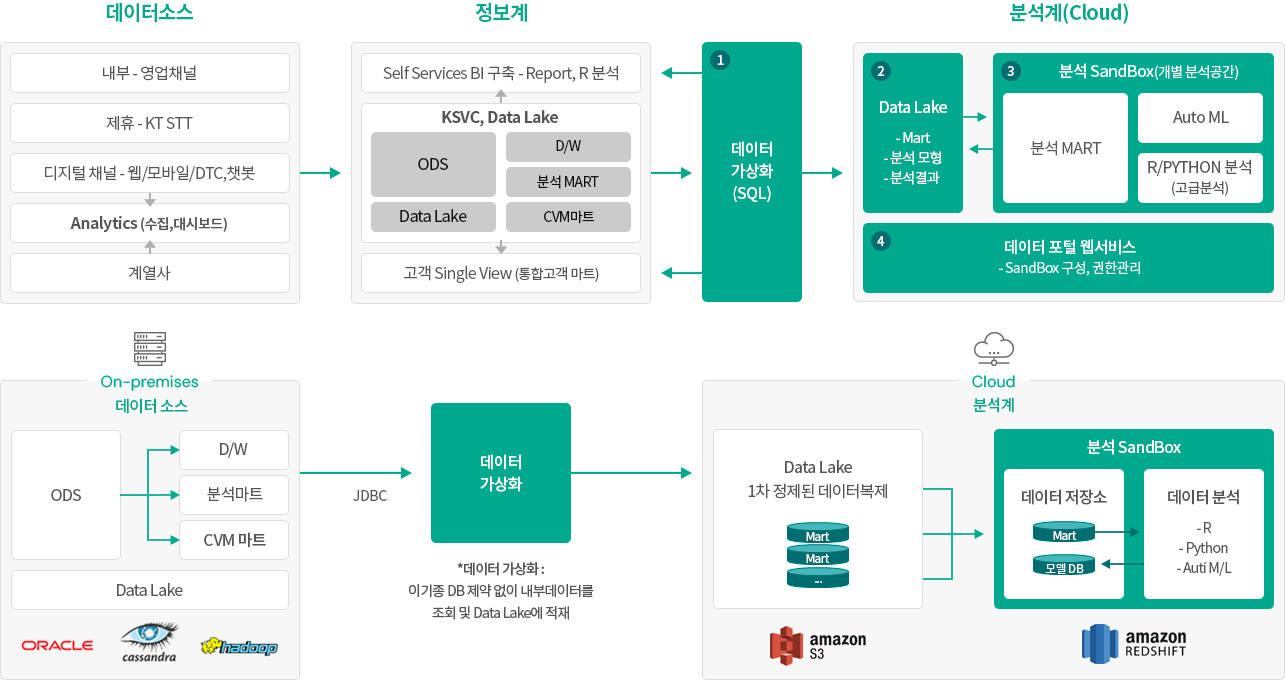
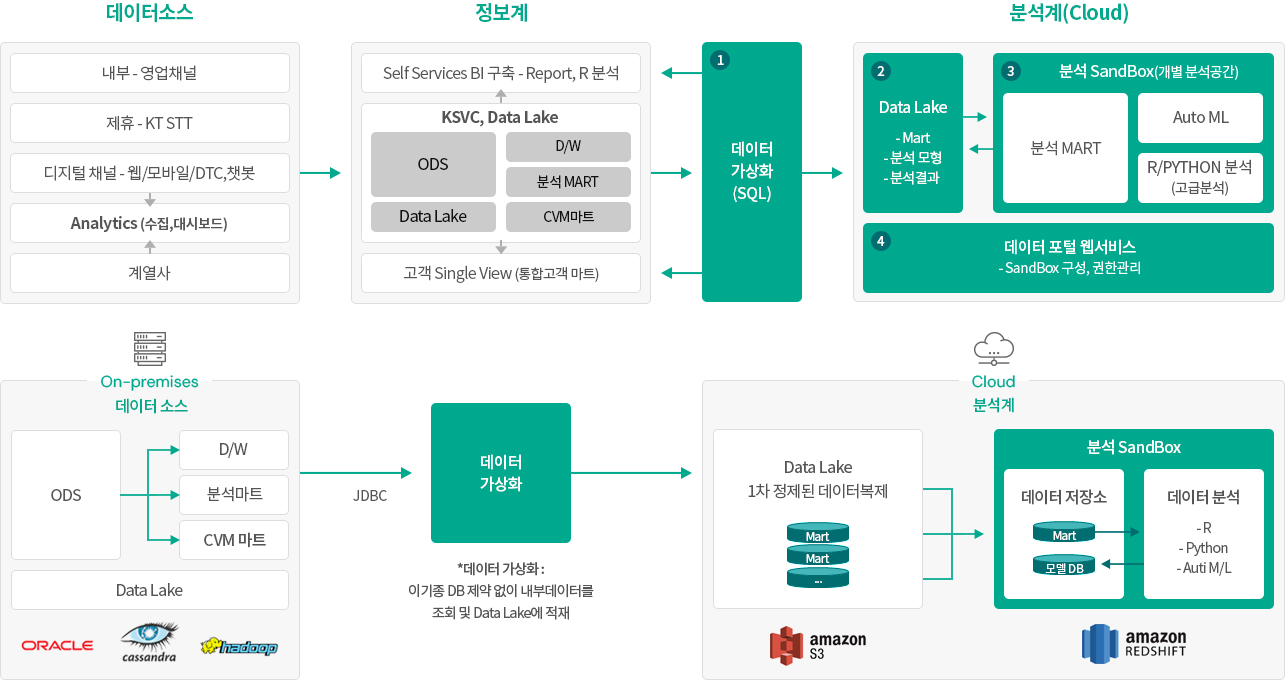
데이터 가상화 DV# 적용 레퍼런스
A 금융사에는 DV#을 활용하여 데이터 분석가(Data Scientist)들에게 기간계/정보계의 다양한 이기종 데이터를 결합/검증할 수 있는 데이터 가상화 공간을 제공하고,
필요한 데이터들은 스케줄링에 의해 Cloud(AWS S3 및 RedShift) 분석환경으로 데이터를 이행까지 수행하였습니다.
| AS-IS >TO-BE 환경 분석 | |||
|---|---|---|---|
| AS-IS |
분석환경
|
데이터 준비 및 품질
|
데이터 활용 및 코드 관리
|
| TO-BE |
|
|
|
데이터 가상화 구축 아키텍처
|