

-
Events
Join us &
Share the inspirationen-space는 엔코아가 진행하고 참여하는 다양한
Contact Us
이벤트와 프로모션 정보를 공유합니다.
고객과 IT 담당자들을 위한 전문적인
컨텐츠도 확인할 수 있습니다.
tech 그래프 데이터베이스의 IFA (Index-Free-Adjacency)
2023.02.20 15:19- 작성자 관리자
- 조회 2,491
그래프 데이터베이스의 IFA (Index-Free-Adjacency)
- DSC 센터장 최미영 -
안녕하세요, 엔코아 DSC에서 그래프데이터베이스 관련 첫번째 블로그를 게재합니다.
그래프데이터베이스에 대해 시작하는 내용으로 그래프데이터베이스가 무엇인가를 소개하지는 않겠습니다. 그 보다는 왜 그래프데이터베이스를 사용해야 하는가를 소개하겠습니다.
그래프데이터베이스는 앞으로는 GDB, 그리고 지금 현실세계에서 가장 많이 사용하는 관계형데이터베이스는 RDB로 줄여서 이야기하겠습니다. GDB와 RDB의 가장 큰 차이점은 RDB는 정규화 작업을 거친 데이터를 질의(Query)에 대응할 때 거의 매번 JOIN을 수행해야 하지만, GDB는 연결되어야 할 데이터는 저장시점부터 연결되어 있으므로 조인의 필요성이 없습니다.
(https://neo4j.com/developer-blog/will-it-graph-identifying-a-good-fit-for-graph-databases-part-1/)
GDB에서는 데이터 요소가 연결되어 있다는 것을 알고 있으므로 노드에 저장된 관계의 순서를 따라가면 됩니다. 이를 Index Free Adjacency(IFA)라고 부릅니다.
IFA는 RDB와 비교하여 GDB의 성능 최적화를 이해하는데 중요한 요소입니다. IFA는 원하는 결과를 사용자에게 return하는 성능은 그래프의 전체 크기에 의존하지 않고 찾아가야 하는 노드에 연결된 관계의 수에만 의존합니다.
그러면, GDB에서 강조하는 IFA는 어떤 구조로 저장되고 관리되는지 좀 더 자세히 확인해보도록 하겠습니다. GDB 내부 구조는 GDB의 종류에 따라 조금씩 다르지만 본 게시물에서는 Neo4J의 저장 구조를 기본으로 설명하겠습니다. 향후 IFA의 구조가 GDB마다 많은 차이가 있는 것이 연구되면 비교 자료를 후속으로 올리겠습니다.
|
Store File |
Record size |
Contents |
|
neostore.nodestore.db |
15B * |
Nodes |
|
neostore.relationshipstore.db |
34B |
Record size |
|
neostore.propertystore.db |
41B |
Properties for nodes and relationships |
|
neostore.propertystore.db.strings |
128B |
Values of string properties |
|
neostore.propertystore.db.arrays |
128B |
Values of array properties |
|
Indexed Property |
1/3* AVG(X) |
Each index entry is approximately 1/3 of the average property value size |
위의 표는 가장 최근(2023.01.05)까지 https://neo4j.com/developer/kb/understanding-data-on-disk/ 에 올라온 Neo4J File 구조의 일부입니다. Neo4J에서는 노드(node), 관계(relationship), 속성(property) 들을 각각 별개의 파일로 관리합니다. 위의 파일들이 Neo4J에서 하나의 DB를 만들 때 생성되는 전체 파일들은 아닙니다. 전체는 약 30여개가 만들어지고 이에 대한 초기 크기는 전체 273M를 차지하고 있습니다. (https://neo4j.com/developer/kb/understanding-database-growth/)이에 대해서는 다른 게시물에서 좀 더 자세히 설명하도록 하겠습니다.
표에서 볼 수 있듯이 노드는 neostore.nodestore.db 라는 파일에서 관리되고 하나의 노드는 15Bytes의 고정길이를 할당 받습니다. 마찬가지로 관계는 neostore.relationshipstore.db 라는 파일에서 관리되고 하나의 관계에 대해 34Bytes를 할당 받습니다. 노드와 관계가 할당받는 Byte의 수는 Neo4J 관련 책이나 블로그에 따라 조금씩 차이가 있어 어느 것이 정말 정확한지 확인이 어렵습니다. 이 게시물에서는 Neo4J 현직 개발자들이 작성한 책(Graph databases 2nd Edition, Ian Robinson, Dr. Jim Webber, Emil Eifrem, 2015, O’Reilly)과 2023년 1월13일까지 Neo4J 홈페이지에서 공식적으로 게시된 게시물을 따릅니다. (https://neo4j.com/developer/kb/understanding-data-on-disk/)
책에서 보인 노드와 관계가 각각 할당 받은 Byte들을 어떻게 사용하고 있는지는 그림과 같습니다. 그림이 실린 책의 내용대로 좀 더 자세한 설명한 구조를 제가 그려 보았습니다. 그런데 여기에서 주소를 지정하기 위한 Bytes 수가 Neo4J Version5가 되면서 좀 더 커졌습니다. 그리고 그에 대한 자세한 설명은 없으므로 현재는 책과 홈페이지 기준으로 먼저 설명 합니다.
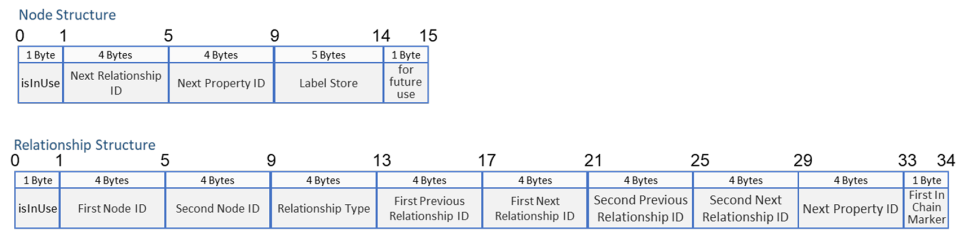
그림에서와 같이 노드와 관계의 첫번째 비트는 해당 노드와 관계를 생성한 이후에 만일 삭제가 되었다면 사용되지 않는다고 표시하고 해당 노드의 ID를 neostore.nodestore.db.id 라는 파일에 기록합니다. neostore.nodestore.db.id는 정확한 비교는 어려워도 Oracle의 FreeList와 같은 역할을 하는 것으로 보입니다. 이렇게 노드와 관계가 고정된 길이로 생성되기 때문에 neostore.nodestore.db 파일에서는 찾고자 하는 노드 record의 위치 주소를 파일내에서 관리하지 않습니다. 이러한 특성이 GDB에서는 성능향상 요소라고 이야기하기도 합니다.
이 그림은 책(Graph databases 2nd Edition, Ian Robinson, Dr. Jim Webber, Emil Eifrem, 2015, O’Reilly)에소개된 것으로 위에서 할당된 Byte들의 정보에 따라 노드와 관계가 어떻게 물리적으로 연결될 수 있는지 보여주고 있습니다. 즉, Node 1은 [LIKES]라는 관계 Type을 가리키는 주소를 4Bytes에 저장하고 ‘name’이라는 첫번째 Property의 주소를 4Bytes에 저장합니다. Label의 경우 5Bytes보다 적으면 노드 record에 그냥 저장하지만 ‘Person’과 같이 5Bytes가 넘으면 해당 Label을 별도의 파일에 저장하고 그 주소를 노드 record 안에 저장합니다.
관계의 경우 노드와 동일하게 첫 Byte는 사용 유무를 기록합니다. 그 다음 4개의 Bytes는 그림에서는 First Node ID라고 되어 있으나 책의 6-5 그림과 견주어 본다는 관계의 start node id 라고 할 수 있고 다음 4 Bytes는 Second Node id 이어도 관계의 end node id로 보시면 더 이해하기가 쉬울 거 같습니다. 그 다음 4Bytes는 관계 Type을 가리키는 주소로 노드와 같이 4Bytes 이하라면 관계 record안에 기록하는 것이 아니라 반드시 다른 파일에 있는 record의 주소를 저장합니다. 이것은 아마 노드 생성시 Label 부여는 필수가 아니지만 관계 생성시의 relationship Type 부여는 필수이기 때문으로 보입니다. Relationship record의 14번째부터 4 Bytes씩 이어지는 4개의 Relationship ID들은 각각 First Previous Relationship ID, First Next Relationship ID, Second Previous Relationship ID, Second Next Relationship ID라고 하지만 그림 6-5에서와 같이 Start Node’s Previous Relationship ID, Start Node’s Next Relationship ID, End Node’s Previous Relationship ID, End Node’s Next Relationship ID로 이해하면 Native GDB의 데이터 구조가 Doubly Linked List 구조라는 면에서의 설명과 더 부합될 것으로 보입니다. 관계 record의 30번째부터 4 Bytes는 노드 record와 같이 관계 record의 첫번째 Property의 주소를 4Bytes에 저장합니다. 노드와 관계 record의 마지막 1Byte 들의 용도는 구체적으로 명시된 것이 없어 현재의 이름 그대로만 이해해 주시기 바랍니다.
다음 그림은 위에 설명된 대로 저장된 노드와 관계의 record 구조에 따라 GDB가 질의에 어떻게 대응하는지를 단계적으로 보입니다. 아래의 예제는 Neo4J Academy에서 더 자세히 확인할 수 있습니다. (https://graphacademy.neo4j.com/courses/neo4j-fundamentals/2-property-graphs/2-native-graph)
림과 같이 GDB 데이터는 위에 정의된 노드와 관계 record 구조에 따라 다음과 같이 간략하게 표현할 수 있습니다.
이 경우에 사용자가 아래의 질의문을 수행하고 그 결과를 얻고자 한다면,
MATCH (n) <-- (:Group) <-- (:Group) <-- (:Group {id: 3}) RETURN n.id
GDB에서 결과를 획득하는 순서는 아래와 같습니다.
보시는 분들의 선호도가 다를 거 같아 Neo4J 원본의 그림과 제가 이해한 순서에 따른 그림을 같이 보이니 취향에 따라 이해 부탁드립니다.
이렇게 노드와 관계의 링크된 주소에 따라 이동하는 IFA 기능때문에 GDB에서는 처음 값(Anchor)을 찾은 이후에는 JOIN없이 연결된 데이터를 사용자에게 return할 수 있습니다.
RDB에서 데이터 연결을 위한 JOIN을 할 때는 일반적으로 아래 그림과 같은 B-Tree의 Leaf Block에서 처음값을 찾는 Index Lookup과 해당 값의 ROWID로 Table Scan을 합니다. 이것도 조인하는 테이블에 Index가 적절하게 잘 구성되었을 경우입니다. 아래 그림은 Oracle의 Index에 대한 내부 구조로 (https://docs.oracle.com/cd/B19306_01/server.102/b14220/schema.htm#sthref1038)에 소개되었습니다.
이와 같이 IFA에 대해 알아보았습니다. 그렇지만 IFA라는 특성 때문에 GDB에서 Index를 아예 사용하지 않는 것은 절대 아닙니다. GDB에서도 index는 여전히 사용됩니다. RDB에서처럼 연결된 노드를 찾기 위해서가 아닌 그래프 횡단에서 시작점(anchor)을 찾는데 일반적으로 사용되며 RDB와 같이 B- Tree로 Unique / NonUnique 로 구축할 수 있습니다.
게시물을 보시고 궁금한 사항은 질문 부탁드립니다. 여러분의 질문에 답을 찾는 과정이 GDB를 이해하는 데 많은 도움이 될 것입니다.
다음에는 같은 데이터를 RDB와 GDB로 구축하고 같은 결과를 각각 SQL과 GQL로 얻을 때 정확히 IFA에 어떤식으로 작동되는지 그에 따른 성능은 어떻게 다른지에 대해 정리하여 올리도록 하겠습니다.
감사합니다.
| 다음글 | Neo4j 구조 톺아보기 | 2023-02-20 |
|---|---|---|
| 이전글 | 엔코아 구독형 데이터 관리 솔루션 영업 파트너사 모집! | 2022-09-01 |